
Unit tests for a parser
As I’ve been implementing my SQL parser, I’ve gone through several iterations of how to actually test it.
Testing the AST
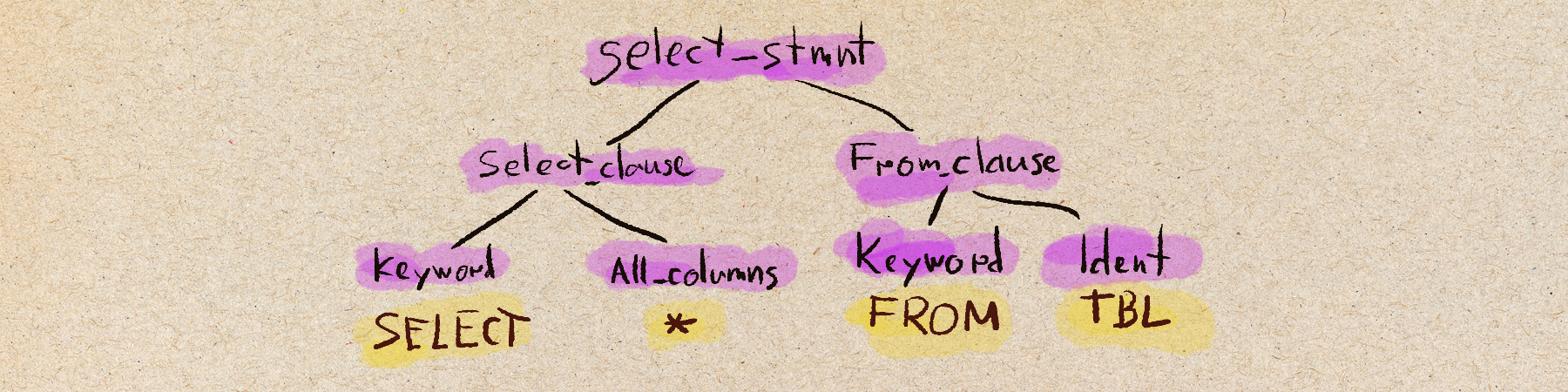
As the whole purpose of a parser is to turn source code into an abstract syntax tree (AST), the most obvious approach is to simply test that given input produces the AST:
expect(parse("SELECT id FROM tbl")).toEqual({
type: "select_stmt",
clauses: [
{ type: "select_clause", columns: [{ type: "identifier", name: "id" }] },
{ type: "from_clause", expr: { type: "identifier", name: "tbl" } },
],
});
This sort of test is perfectly fine… as long as you only have a few of them. When you want to write hundreds or maybe even thousands of tests, this approach starts to become problematic:
- It’s very tedious to write out these syntax trees manually, the above example is in the most simpler side of things.
- Unless you are writing a parser to output some standardised AST, the structure of the AST will likely evolve considerably over the course of development. If you hard-code the specific AST in you tests, these tests become a huge maintenance burden.
- The AST will take up a considerable amount of space in your tests, dwarfing the size of the input source code. This makes your test files bloated.
- Reading these AST-s is hard for the human brain. They tend to be very repetitive in nature. You’ll often want to test some subtle variations of source code, which will produce some tiny change in the AST, often in a single node several levels deep. Such differences are really hard to spot.
Snapshots to the rescue
One simple remedy is to use auto-generated snapshots, like those supported by Jest:
expect(parse("SELECT id FROM tbl")).toMatchInlineSnapshot();
Running the test for a first time will generate a snapshot of the produced AST:
expect(parse("SELECT id FROM tbl")).toMatchInlineSnapshot(`
{
"clauses": [
{
"columns": [
{
"name": "id",
"type": "identifier",
},
],
"type": "select_clause",
},
{
"expr": {
"name": "tbl",
"type": "identifier",
},
"type": "from_clause",
},
],
"type": "select_stmt",
}
`);
This approach eliminates the work for writing out the AST manually and it also simplifies maintenance, one can easily re-generate all the snapshots when your AST structure changes.
However, lots of the problems still remain:
- The snapshots tend to be even longer than the manually written AST.
- Readability can be even worse: you’ll lose syntax highlighting, the type field appears last because of alphabetized ordering (which is really unhelpful for understanding the AST).
You could also save the snapshots into a separate file - that would eliminate the huge snapshots from your actual test files. But that’s more like showing the problem under a carpet.
Serializing the tree
Several parsers also come with a serializer, which takes the AST as an input and outputs source code. To test the serializer one would now need to write all the same tests as one has written for the parser, but in reverse. That would be excessive, to say the least.
Instead, one can test both parsing and serializing in tandem:
expect(serialize(parse("select id from tbl"))).toEqual("SELECT id FROM tbl");
This is a huge win for the quality of our tests:
- the tests are now really succinct and easily readable.
- the tests will not be effected by changes in the AST.
One might argue that tests like these don’t properly test the output of our parse() function, as no code inside our tests is inspecting the produced AST. Even when one considers the serializer to be part of our tests, there’s no guarantee that the serializer will inspect all parts of the AST.
This is a valid critique.
However the only scenario that can slip though such a test is when the parser adds some extra info to the AST, which isn’t actually needed by the serializer. That’s a general problem which will always plague us when we don’t test what I like calling „the whole world“. Our serializer will check everything in AST that it expects to be there, but it will not report on things that should not be present (like AST Node object having extra fields it should not have).
Luckily there’s a way to protect us against this problem: static types. When your AST structure is strictly typed, it will be much less likely that you mistakenly add a field that should not be there.
That said, you probably still want to have at least some tests for the actual AST structure.
Especially if you have cases where different AST structures produce the same serialization.
(Like ensuring that true is parsed as {type: "boolean", value: true}
not as {type: "identifier", name: "true"}.)
But such cases should be relatively rare.
Taking it even further
In practice the output expected from serializer is often exactly the same as the input given to the parser. In these cases we can make our tests even shorter:
function test(sql) {
expect(serialize(parse(sql))).toEqual(sql);
}
test("SELECT 1, 2, 3");
test("SELECT * FROM tbl");
test("SELECT id FROM tbl");
That’s the approach I’ve taken with most of the tests for my SQL parser CST, which outputs a CST (concrete syntax tree) rather than an AST (abstract syntax tree), with the goal there being able to accurately reproduce the input source code from the CST alone.
That approach might not be fully applicable to all parsers, but I think one could still write a large number of tests in such a minimalist way.
Happy testing!